Overview
Skipper Seabold, a well known contributor to the PyData community, recently gave a talk titled “What’s the Science in Data Science?”. His talk presents several methods commonly used in econometrics that could benefit the field of data science if more widely adopted. Some of the methods were:
- Instrumental Variables
- Matching
- Difference-in-Differences
These modeling techniques are popular for discovering causal relationships in observational studies. When an RCT (randomized control trial) is unreasonable then these techniques can sometimes give us an alternative approach.
I’ll be exploring one of these methods called Instrumental Variables (or IV). An example use case from Skipper’s talk was a study on the Fulton Fish Market in NYC.

The referenced study estimates the demand curve for fish at the market. Finding the demand curve is unfortunately not as simple as regressing quantity on price. The relationship between price and the quantity of fish sold is not exclusive to demand but includes supply effects at the market. We’ll be using IV to account for supply effects to isolate the demand effects.
In this blog post I’ll be reproducing a portion of this analysis using R, packages of the tidyverse, and the brms package in R.
Data
I discovered data related to this study at the following website: http://people.brandeis.edu/~kgraddy/data.html
Bringing this data into R is very simple. The linked dataset appears to be the cleaned and transformed data used within the paper. Let’s read it into our R environment and take a look:
library(tidyverse)
fulton <- read_tsv("http://people.brandeis.edu/~kgraddy/datasets/fish.out")
fulton
# A tibble: 111 x 16
day1 day2 day3 day4 date stormy mixed price qty rainy
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 0 0 0 911202 1 0 -0.431 8.99 1
2 0 1 0 0 911203 1 0 0 7.71 0
3 0 0 1 0 911204 0 1 0.0723 8.35 1
4 0 0 0 1 911205 1 0 0.247 8.66 0
5 0 0 0 0 911206 1 0 0.664 7.84 0
6 1 0 0 0 911209 0 0 -0.207 9.30 0
7 0 1 0 0 911210 0 1 -0.116 8.92 0
8 0 0 1 0 911211 0 0 -0.260 9.11 1
9 0 0 0 1 911212 0 1 -0.117 8.31 0
10 0 0 0 0 911213 0 0 -0.342 9.21 0
# … with 101 more rows, and 6 more variables: cold <dbl>,
# windspd <dbl>, windspd2 <dbl>, pricelevel <dbl>, totr <dbl>,
# tots <dbl>Here is a quick description of the variables we will be using for this work:
| Variable | Units | Description |
|---|---|---|
| qty | log(pounds) | The total amount of fish sold on a day |
| price | log($/lb) | Average price for the day |
| day1-day4 | dummy var | Monday-Thurs |
| cold | dummy var | Weather on shore |
| rainy | dummy var | Rain on shore |
| stormy | dummy var | Wind and waves off shore (a 3-day moving average) |
The paper informs the reader that transactions recorded are of a particular fish species called Whiting. We can get a feel for the total amount of Whiting being sold by reproducing Figure 2 from the paper.
# fixing the date column
fulton %>%
mutate(
date = as.character(date),
date = parse_date(date, format = "%y%m%d")
) %>%
ggplot(aes(x = date, y = exp(qty))) +
geom_col() +
labs(
title = "Figure 2",
subtitle = "Daily Volumes of Whiting",
x = "Date (December 2, 1991-May 8, 1992)",
y = "Quantity (pounds)"
)

Reproducing this figure gave me confidence that I had the correct data to reproduce the analysis.
Demand Curve
The naive approach to finding the relationship between price and demand (the demand curve) would be to regress quantity on price:
ggplot(fulton, aes(x = price, y = qty)) +
geom_point() +
geom_smooth(method = "lm")

But would this be the demand curve? No, it actually wouldn’t be. According to intro economics, each one of the points in the plot above is the result of the intersection of both a supply and demand curve. Something like this figure:
So how does the author go about estimating a more accurate representation of the demand curve? How do you isolate the demand effects from the supply? Well, it’s in the title of this post: Instrumental Variables.
Skipper’s presentation explained IV as:
We can replace X with “instruments” that are correlated with X but not caused by Y or that affect Y but only through X.
Regressions
The paper includes a table of estimated coefficients shown here:
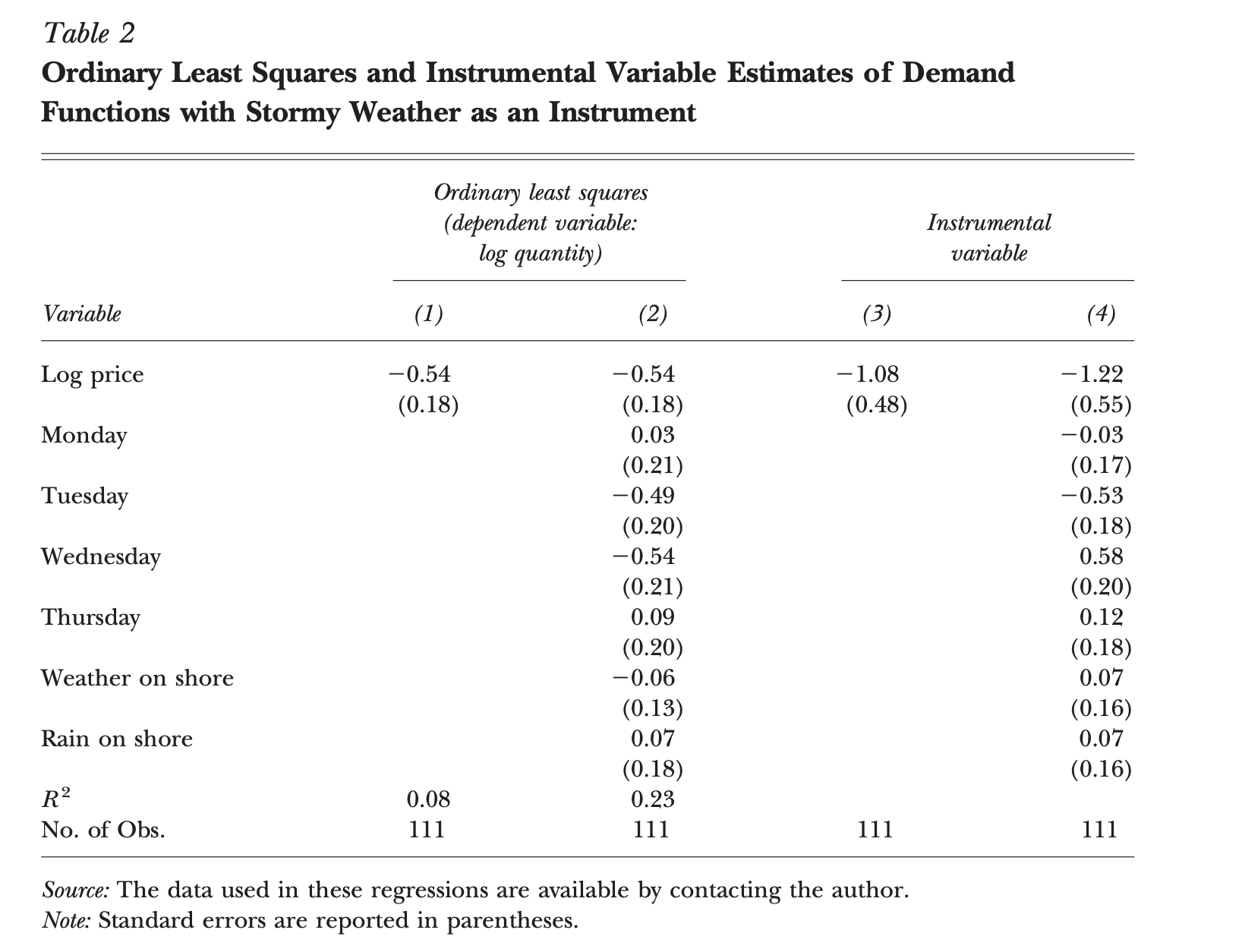
I’ll be reproducing this table but with Bayesian estimation. A nice benefit of using Bayesian estimation is that our estimated model includes distributions for each of our parameters. We’ll be visualizing these distributions for comparing results to the table above.
OLS (Ordinary Least Squares) Reproduced
First, let’s perform the classic linear regression. We can use the brm function in the brms package as a drop in replacement for R’s linear model function lm. However, the estimation process of lm and brm are quite different. The lm function is using OLS and the brms package is performing Bayesian estimation using a form of Markov Chain Monte Carlo (MCMC).
Starting with column 1 of table 2 we estimate the coefficients with only qty and price:
library(brms)
library(tidybayes)
library(ggridges)
# column 1 in table 2
fit1 <- brm(qty ~ price, data = fulton, refresh = 0)
fit1 %>%
posterior_samples() %>%
ggplot(aes(x = b_price)) +
geom_density_line()

The brms package provides an abstraction layer to the Stan probabilistic programming language. So if you’re curious what the weakly informative priors that I breezed over actually are, take a look at the generated code with the stancode function. Here is an excerpt of the stan code generated for the model above:
model {
vector[N] mu = temp_Intercept + Xc * b;
// priors including all constants
target += student_t_lpdf(temp_Intercept | 3, 9, 10);
target += student_t_lpdf(sigma | 3, 0, 10)
- 1 * student_t_lccdf(0 | 3, 0, 10);
// likelihood including all constants
if (!prior_only) {
target += normal_lpdf(Y | mu, sigma);
}
}Moving to column 2 of table 2 we estimate the model including the dummy day variables, cold, and rainy variables:
# column 2 in table 2
fit1_full <- brm(
qty ~ price + day1 + day2 + day3 + day4 + cold + rainy,
data = fulton,
refresh = 0
)
# a plot of parameter estimates
fit1_full %>%
posterior_samples() %>%
gather(b_price:b_rainy, key = "coef", value = "est") %>%
ggplot(aes(x = est, y = coef)) +
geom_density_ridges()

We can see that the estimated coefficient for price in this context is the same for both the simple linear regression and the regression accounting for weekday and onshore weather.
IV Reproduced
Before performing the estimation I wanted to add a quote from the paper. I thought Kathryn Graddy explained the IV estimation well:
That is, first a regression is run with log price as the dependent variable and the storminess of the weather as the explanatory variable. This regression seeks to measure the variation in price that is attributable to stormy weather. The coefficients from this regression are then used to predict log price on each day, and these predicted values for price are inserted back into the regression.
Kathryn mentions two steps here:
- A regression with log price and storminess
- Using coefficients from step
1, predict log price and place the predicted values back into the second regression.
A simple diagram of this two step process is generated below:
library(ggdag)
dagify(
qty ~ price,
price ~ stormy
) %>%
ggdag(seed = 12) +
theme(
panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank()
)

Now let’s perform the estimation. This is possible with the brms package and its ability to specify multivariate response models. We’ll piece it together with two separate formulas defined in the bf function calls below.
The first estimation will be for column 3 of table 2:
# measure variation in price attributable to stormy weather
fit2a <- bf(price ~ stormy)
# estimate demand
fit2b <- bf(qty ~ price)
# column 3 in table 2
fit2 <- brm(fit2a + fit2b, data = fulton, refresh = 0)
fit2 %>%
posterior_samples() %>%
ggplot(aes(x = b_qty_price)) +
geom_density_line()

And lastly we’ll estimate the IV with the remaining variables (column 4):
# visual representation of the estimation
dagify(
qty ~ price + day1 + day2 + day3 + day4 + cold + rainy,
price ~ stormy
) %>%
ggdag(seed = 9) +
theme(
panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank()
)

# add additional demand specific variables
fit2b_full <- bf(qty ~ price + day1 + day2 + day3 + day4 + cold + rainy)
# column 4 in table 2
fit2_full <- brm(fit2a + fit2b_full, data = fulton, refresh = 0)
fit2_full %>%
posterior_samples() %>%
gather(b_qty_price:b_qty_rainy, key = "coef", value = "est") %>%
ggplot(aes(x = est, y = coef)) +
geom_density_ridges()

One thing that I think is particularly interesting about the distributions above is the uncertainty of the price coefficient. We can clearly see that the parameter’s distribution with IV is much wider than our classic linear regression. Here we are seeing the uncertainty of our first model (price ~ storminess) propagating to our second model.
Visualizing the Demand Curve
Now we can plot the demand curve with isolated demand effects. I’ll use the first IV estimation with only qty, price, and stormy variables:
fulton %>%
add_predicted_draws(fit2) %>%
filter(.category == "qty") %>%
ggplot(aes(x = price, y = qty)) +
stat_lineribbon(
aes(y = .prediction),
.width = c(.99, .95, .8, .5),
color = "#08519C"
) +
geom_point(data = fulton, size = 2) +
scale_fill_brewer()

The prediction is downward trending as the original curve except with a steeper slope (-0.54 vs -1.06).
Elasticities
The paper breaks down the interpretation of the estimated coefficients in terms of elasticities. Given that we have taken the log of both our quantity and price the coefficients can be interpreted in a clever way. Let’s take a look at why this is the case:
If we take the log of both \(y\) and \(x\) of our linear model:
\[ \text{log}(y) = \beta_0 + \beta_1\text{log}(x) + \epsilon \] Now solve for \(y\) to find the marginal effects:
\[ y = e^{\beta_o + \beta_1\text{log}(x) + \epsilon} \] Then differentiate with respect to \(x\):
\[ \frac{dy}{dx} = \frac{\beta_1}{x}e^{\beta_o + \beta_1\text{log}(x) + \epsilon} = \beta_1 \frac{y}{x} \]
If you then solve for \(\beta_1\) you find:
\[ \beta_1 = \frac{dy}{dx} \frac{x}{y} \] So here \(\beta_1\) is an elasticity. For a \(\%\) increase in \(x\) there is a \(\beta_1 \%\) increase in \(y\).
Elasticities are commonly summarized in a table like this:
| Elasticity | Value | Description |
|---|---|---|
| Elastic | | E | > 1 | % change in Q > % change in P |
| Unitary Elastic | | E | = 1 | % change in Q = %change in P |
| Inelastic | | E | < 1 | % change in Q < % change in P |
Given the descriptions of elasticity above. We would have two different interpretations of how demand responds to price with the non-IV and the IV estimation. With the non-IV estimation our elasticity coefficient is -0.54 [-0.89, -0.19]. With the IV estimation our elasticity is -1.06 [-2.18, -0.15]. So we would mistakenly interpret the demand elasticity as being inelastic when it actually appears to be unit elastic.
Some interesting interpretations of this unit elasticity from the paper include:
First, it is consistent with pricing power on the part of the fish dealers. A price-setting firm will raise price to the point where the percentage change in the quantity demanded is at least as large as the percentage change in price; otherwise, it would make sense to raise the price even more
Second, when demand has a unitary elasticity, it means that the percentage change in quantity would always equal the percentage change in price, and the weather would therefore not have much effect on a seller’s revenue, keeping fishermen’s incomes relatively constant.
Third, unit elasticities could also result from budget constraints on the part of some buyers.
Wrapping Up
This was definitely a fun topic to start exploring. I plan on taking a look at difference-in-differences in the near future as well.
References
- What’s the Science in Data Science?
- Graddy, Kathryn. 2006. “Markets: The Fulton Fish Market.” Journal of Economic Perspectives, 20 (2): 207-220.
- Create supply and demand economics curves with ggplot2
- Michael Betancourt: “A Conceptual Introduction to Hamiltonian Monte Carlo”, 2017